알고리즘 헤더파일에는 배열의 정렬을 쉽게 처리해주기 위한 sort가 내장되어 있습니다.
오름차순 정렬, 내림차순 정렬과 Pair가 있을 때 내맘대로 정렬하는 법을 살펴보겠습니다.
1. 오름차순 정렬
정렬할 배열과 범위를 정해주면, 기본적으로 오름차순으로 정렬해줍니다.
c++의 sort함수는 quick sort로 구현되어 있습니다.
sort(a, a + 10, less< 자료형>());
오름차순이 기본이므로, 세번째 인자를 제외해도 오름차순 정렬이 됩니다.
sort(a, a + 10);
#include <iostream>
#include <algorithm>
#include <vector>
#include <string>
using namespace std;
int main()
{
int a[10] = { 1,5,4,6,7,10,9,2,3,8 };
sort(a, a + 10);
for (int i = 0; i < 10; i++)
{
cout << a[i] << " ";
}
return 0;
}
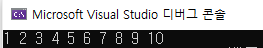
2. 내림차순 정렬
정렬할 배열과 범위를 정해주고 인자 greater<자료형>()를 추가하면, 내림차순으로 정렬해줍니다.
sort(a, a + 10, greater<자료형>());
#include <iostream>
#include <algorithm>
#include <vector>
#include <string>
using namespace std;
int main()
{
int a[10] = { 1,5,4,6,7,10,9,2,3,8 };
sort(a, a + 10, greater<int>());
for (int i = 0; i < 10; i++)
{
cout << a[i] << " ";
}
return 0;
}
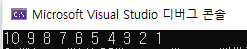
3. Pair 정렬
기본적으로 first를 기준으로 정렬되고, first가 같으면 second를 기준으로 정렬됩니다.
코드로 살펴보겠습니다.
#include <iostream>
#include <algorithm>
#include <vector>
#include <string>
using namespace std;
int main()
{
vector <pair<int, int> > v;
v.push_back(make_pair(1, 1));
v.push_back(make_pair(2, 1));
v.push_back(make_pair(3, 3));
v.push_back(make_pair(3, 2));
v.push_back(make_pair(3, 1));
sort(v.begin(), v.end());
for (int i = 0; i < v.size(); i++)
{
cout << v[i].first << " " << v[i].second << "\n";
}
return 0;
}
first로 3이 중복되지만, second는 모두 다릅니다. v를 오름차순 정렬한 결과는 다음과 같습니다.
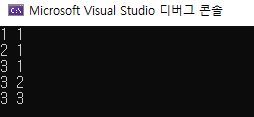
first를 기준으로 먼저 정렬한 다음, second를 기준으로 정렬한 모습을 보실 수 있습니다.
위 예제대로만 모든 문제가 풀린다면 행복할 것 같습니다. 하지만 알고리즘은 실전입니다(출처: 내 뇌).
다음 문제로 살펴보겠습니다.
내맘대로 정렬을 이용한 풀이 - 1969번: DNA
1969번: DNA
DNA란 어떤 유전물질을 구성하는 분자이다. 이 DNA는 서로 다른 4가지의 뉴클레오티드로 이루어져 있다(Adenine, Thymine, Guanine, Cytosine). 우리는 어떤 DNA의 물질을 표현할 때, 이 DNA를 이루는 뉴클레오
www.acmicpc.net
문제의 요지는, 해밍 거리는 제일 작으면서, 사전순으로 가장 작은 DNA를 구해야 한다는 것입니다.
다음과 같은 벡터를 선언해 봅시다.
vector<pair<int, char> > v;v벡터의 first는 숫자고, second는 글자입니다.
제가 하고 싶은 것은, A, C, G, T를 넣어 각 DNA의 인덱스와 비교하고, 일단 거리를 int에 넣고 해당 글자를 char에 넣는 것 입니다.
for (int i = 0; i < m; i++)
{
vector<pair<int, char> > v;
int a_cnt = 0, c_cnt = 0, g_cnt = 0, t_cnt = 0;
for (int j = 0; j < n; j++)
{
if (str[j][i] == 'A') a_cnt++;
if (str[j][i] == 'C') c_cnt++;
if (str[j][i] == 'G') g_cnt++;
if (str[j][i] == 'T') t_cnt++;
}
v.push_back({ a_cnt, 'A' });
v.push_back({ c_cnt, 'C' });
v.push_back({ g_cnt, 'G' });
v.push_back({ t_cnt, 'T' });입력된 여러 DNA의 각 인덱스마다 A, C, G, T의 카운트를 세고, 위 벡터에 저장해주었습니다.
first를 기준으로 내림차순으로 정렬하고, 만약 first가 같다면, seond를 기준으로 오름차순으로 정렬해주면 v의 0번째 인덱스는 거리도 제일 짧고 알파벳 순으로도 제일 앞에 있는 뉴클레오티드일 것입니다.
그래서 아까 배웠던 인자에 greater을 넣으려고 봤더니.. 자료형이 달라서 추가하기가 머리가 아픕니다.
c++에서는 커스텀 compare를 이용해 내 맘대로 정렬을 할 수 있습니다.
4. 내맘대로 정렬 - Compare 함수 추가하기
다음과 같이 compare함수를 추가하여 내맘대로 정렬을 할 수 있습니다. compare함수는 직접 구현해야 합니다.
sort(v.begin(), v.end(), compare);sort함수는 두가지 함수를 받아 비교 후, boolean을 통해 두 인자의 대소를 비교하여 정렬합니다.
DNA문제에서, 우리는 첫번째 인자가 제일 크도록, 두번째 인자는 사전순으로 제일 작은 수가 오도록 정렬하고 싶습니다.
sort함수가 요구하는 것 처럼, 우리가 원하는 정렬을 하도록 boolean을 반환하는 함수를 다음과 같이 작성해 봅시다.
설명이 있으니 일단 마음편히 보시면 될 것 같습니다!
bool compare(pair<int, char>& front, pair<int, char>& back)
{
int front_cnt = front.first;
char front_char = front.second;
int back_cnt = back.first;
char back_char = back.second;
if (front_cnt < back_cnt) return front_cnt > back_cnt;
else if (front_cnt == back_cnt) return front_char < back_char;
else return front_cnt > back_cnt;
}감이 살짝 오시나요? 한줄 한줄 무얼 의미하는지 살펴볼게요!
//함수의 선언부
bool compare(pair<int, char>& front, pair<int, char>& back)boolean 타입을 반환하는 compare 함수입니다. 이 함수는 내부적으로 pair을 받아 front, back에 저장하여 대소를 비교하여 결과를 반환합니다.
Q1. 엥?? pair가 왜 갑자기 나오나요??
A: 아까 위에서 이 문제를 정의할 때 v는 pair<int, char>의 짝꿍을 가지는 벡터였습니다. 이 함수에서 두개의 v의 pair를 비교하고 대소를 반환하기 위해 위같은 인자를 받도록 합니다.
int front_cnt = front.first;
char front_char = front.second;
int back_cnt = back.first;
char back_char = back.second;앞 뒤 pair를 비교하기 위해선, 각각을 변수로 나누어 비교해야겠죠! 위에서 나눴던 인자를 다시 나누어줍시다.
if (front_cnt < back_cnt) return front_cnt > back_cnt;
else if (front_cnt == back_cnt) return front_char < back_char;
else return front_cnt > back_cnt;제일 중요한 부분입니다.
우리는 first가 제일 크게, first가 서로 같다면, second가 제일 작은 정렬을 수행하고 싶습니다.
따라서 위의 return을 반환하면 내맘대로 정렬이 완료됩니다.
내맘대로 정렬을 이용한 정답은 다음과 같습니다.
#include <iostream>
#include <algorithm>
#include <vector>
#include <string>
using namespace std;
bool compare(pair<int, char>& front, pair<int, char>& back)
{
int front_cnt = front.first;
char front_char = front.second;
int back_cnt = back.first;
char back_char = back.second;
if (front_cnt < back_cnt) return front_cnt > back_cnt;
else if (front_cnt == back_cnt) return front_char < back_char;
else return front_cnt > back_cnt;
}
int main()
{
int n, m, shortest_cnt=0;
int hamming_field[1001] = { 0, };
string str[1001], shortest_dna;
cin >> n >> m;
for (int i = 0; i < n; i++) cin >> str[i];
for (int i = 0; i < m; i++)
{
vector<pair<int, char> > v;
int a_cnt = 0, c_cnt = 0, g_cnt = 0, t_cnt = 0;
for (int j = 0; j < n; j++)
{
if (str[j][i] == 'A') a_cnt++;
if (str[j][i] == 'C') c_cnt++;
if (str[j][i] == 'G') g_cnt++;
if (str[j][i] == 'T') t_cnt++;
}
v.push_back({ a_cnt, 'A' });
v.push_back({ c_cnt, 'C' });
v.push_back({ g_cnt, 'G' });
v.push_back({ t_cnt, 'T' });
sort(v.begin(), v.end(), compare);
shortest_cnt += n - v[0].first;
shortest_dna += v[0].second;
}
cout << shortest_dna << "\n" << shortest_cnt;
return 0;
}DIY compare함수 작성은 pair가 있는 정렬에서 유용하겠습니다.
이해가 되셨다면, 다음 문제도 풀어보세요!
Bonus - 14593번, 2017 아주대학교 프로그래밍 경시대회 (Large)
14593번: 2017 아주대학교 프로그래밍 경시대회 (Large)
아주대학교 프로그래밍 경시대회(Ajou Programming Contest, APC)는 2009년 제1회를 시작으로 2014년 제6회까지 개최된 아주대학교 학생들을 위한 프로그래밍 경시대회이다. 2017년, 다른 학교에서 활발히
www.acmicpc.net
세개의 정수가 순서대로 입력됩니다. 각각의 정수를 편의상 A, B, C라고 부르겠습니다.
여러 참가자중, A가 제일 큰 사람이 우승합니다.
A가 같은 경우, B가 더 작은 사람이 우승합니다.
A와 B가 모두 같은 경우, C가 더 작은 사람이 우승합니다.
흠.... 각각의 사람마다 많은 정보가 주어집니다. 그렇다면, 2개의 쌍을 가지는 벡터를 선언해 내맘대로 정렬을 해볼까요?
typedef pair<int, int> score_pare;
vector<pair <score_pare, score_pare> > v;
pair<int, int>는 항상 쓰기도 손목아프고, 보기도 좋지 않으니, score pare로 바꾸어 쓰겠습니다.
v는 다음과 같은 정보를 저장할 예정입니다.
V [pair(A, B), pair(C, 참가자 번호)]
여기서 질문입니다. V안에는 두개의 pair가 pair 자체로 묶여 저장되어 있습니다.
그렇다면, V.first.first는 뭘까~~~~~요??
바로바로, A입니다!!!!!
pair로 pair를 묶었기 때문에, V.first는 pair(A, B)이고, 여기서 또 V.first.first를 해주면, A가 선택된 것입니다.
꿈속의 꿈속을 탐험하는 인셉션처럼, 우리가 선언한 벡터는 Pair 속에 Pair를 선언한 것이죠.
그렇다면, 문제가 요구하는 것에 따라 내맘대로 정렬을 수행하기 위해 compare함수를 작성해 보겠습니다!
#include <iostream>
#include <algorithm>
#include <vector>
using namespace std;
typedef pair<int, int> score_pare;
vector<pair <score_pare, score_pare> > v;
bool compare(pair<score_pare, score_pare> &front, pair<score_pare, score_pare> &back)
{
int front_s = front.first.first;
int front_c = front.first.second;
int front_l = front.second.first;
int back_s = back.first.first;
int back_c = back.first.second;
int back_l = back.second.first;
if (front_s == back_s)
{
if (front_c == back_c) return front_l < back_l;
return front_c < back_c;
}
return front_s > back_s;
}pair속에 pair가 있는 인자를 각각 front와 back으로 받고, 각각을 변수로 나누어 비교하는 것을 보실 수 있습니다.
V.second.second는 [참가자의 번호]를 나타내고 있으므로 비교하지 않습니다. 정렬이 완료되면, 맨 앞 원소의 참가자 번호를 출력할거니까요!
정답코드는 다음과 같습니다.
#include <iostream>
#include <algorithm>
#include <vector>
using namespace std;
typedef pair<int, int> score_pare;
vector<pair <score_pare, score_pare> > v;
bool compare(pair<score_pare, score_pare> &front, pair<score_pare, score_pare> &back)
{
int front_s = front.first.first;
int front_c = front.first.second;
int front_l = front.second.first;
int back_s = back.first.first;
int back_c = back.first.second;
int back_l = back.second.first;
if (front_s == back_s)
{
if (front_c == back_c) return front_l < back_l;
return front_c < back_c;
}
return front_s > back_s;
}
int main()
{
int n;
int s, c, l;
cin >> n;
for (int i = 1; i <= n; i++)
{
cin >> s >> c >> l;
v.push_back({ {s,c},{l,i} });
}
sort(v.begin(), v.end(), compare);
cout<<v[0].second.second;
return 0;
}'알고리즘' 카테고리의 다른 글
| [BOJ] 14606번. 피자 (0) | 2021.01.22 |
|---|---|
| [BOJ] 1010번. 다리 놓기 (0) | 2021.01.21 |
| 실전 속성! C++ 이것만 알면 된다 (+ 간단 단축키 모음) (0) | 2021.01.18 |
| [BOJ] 1149번.RGB거리 (0) | 2021.01.10 |
| [BOJ] 15649번. N과 M(1) (0) | 2021.01.10 |
알고리즘 헤더파일에는 배열의 정렬을 쉽게 처리해주기 위한 sort가 내장되어 있습니다.
오름차순 정렬, 내림차순 정렬과 Pair가 있을 때 내맘대로 정렬하는 법을 살펴보겠습니다.
1. 오름차순 정렬
정렬할 배열과 범위를 정해주면, 기본적으로 오름차순으로 정렬해줍니다.
c++의 sort함수는 quick sort로 구현되어 있습니다.
sort(a, a + 10, less< 자료형>());
오름차순이 기본이므로, 세번째 인자를 제외해도 오름차순 정렬이 됩니다.
sort(a, a + 10);
#include <iostream>
#include <algorithm>
#include <vector>
#include <string>
using namespace std;
int main()
{
int a[10] = { 1,5,4,6,7,10,9,2,3,8 };
sort(a, a + 10);
for (int i = 0; i < 10; i++)
{
cout << a[i] << " ";
}
return 0;
}
2. 내림차순 정렬
정렬할 배열과 범위를 정해주고 인자 greater<자료형>()를 추가하면, 내림차순으로 정렬해줍니다.
sort(a, a + 10, greater<자료형>());
#include <iostream>
#include <algorithm>
#include <vector>
#include <string>
using namespace std;
int main()
{
int a[10] = { 1,5,4,6,7,10,9,2,3,8 };
sort(a, a + 10, greater<int>());
for (int i = 0; i < 10; i++)
{
cout << a[i] << " ";
}
return 0;
}
3. Pair 정렬
기본적으로 first를 기준으로 정렬되고, first가 같으면 second를 기준으로 정렬됩니다.
코드로 살펴보겠습니다.
#include <iostream>
#include <algorithm>
#include <vector>
#include <string>
using namespace std;
int main()
{
vector <pair<int, int> > v;
v.push_back(make_pair(1, 1));
v.push_back(make_pair(2, 1));
v.push_back(make_pair(3, 3));
v.push_back(make_pair(3, 2));
v.push_back(make_pair(3, 1));
sort(v.begin(), v.end());
for (int i = 0; i < v.size(); i++)
{
cout << v[i].first << " " << v[i].second << "\n";
}
return 0;
}
first로 3이 중복되지만, second는 모두 다릅니다. v를 오름차순 정렬한 결과는 다음과 같습니다.
first를 기준으로 먼저 정렬한 다음, second를 기준으로 정렬한 모습을 보실 수 있습니다.
위 예제대로만 모든 문제가 풀린다면 행복할 것 같습니다. 하지만 알고리즘은 실전입니다(출처: 내 뇌).
다음 문제로 살펴보겠습니다.
내맘대로 정렬을 이용한 풀이 - 1969번: DNA
1969번: DNA
DNA란 어떤 유전물질을 구성하는 분자이다. 이 DNA는 서로 다른 4가지의 뉴클레오티드로 이루어져 있다(Adenine, Thymine, Guanine, Cytosine). 우리는 어떤 DNA의 물질을 표현할 때, 이 DNA를 이루는 뉴클레오
www.acmicpc.net
문제의 요지는, 해밍 거리는 제일 작으면서, 사전순으로 가장 작은 DNA를 구해야 한다는 것입니다.
다음과 같은 벡터를 선언해 봅시다.
vector<pair<int, char> > v;v벡터의 first는 숫자고, second는 글자입니다.
제가 하고 싶은 것은, A, C, G, T를 넣어 각 DNA의 인덱스와 비교하고, 일단 거리를 int에 넣고 해당 글자를 char에 넣는 것 입니다.
for (int i = 0; i < m; i++)
{
vector<pair<int, char> > v;
int a_cnt = 0, c_cnt = 0, g_cnt = 0, t_cnt = 0;
for (int j = 0; j < n; j++)
{
if (str[j][i] == 'A') a_cnt++;
if (str[j][i] == 'C') c_cnt++;
if (str[j][i] == 'G') g_cnt++;
if (str[j][i] == 'T') t_cnt++;
}
v.push_back({ a_cnt, 'A' });
v.push_back({ c_cnt, 'C' });
v.push_back({ g_cnt, 'G' });
v.push_back({ t_cnt, 'T' });입력된 여러 DNA의 각 인덱스마다 A, C, G, T의 카운트를 세고, 위 벡터에 저장해주었습니다.
first를 기준으로 내림차순으로 정렬하고, 만약 first가 같다면, seond를 기준으로 오름차순으로 정렬해주면 v의 0번째 인덱스는 거리도 제일 짧고 알파벳 순으로도 제일 앞에 있는 뉴클레오티드일 것입니다.
그래서 아까 배웠던 인자에 greater을 넣으려고 봤더니.. 자료형이 달라서 추가하기가 머리가 아픕니다.
c++에서는 커스텀 compare를 이용해 내 맘대로 정렬을 할 수 있습니다.
4. 내맘대로 정렬 - Compare 함수 추가하기
다음과 같이 compare함수를 추가하여 내맘대로 정렬을 할 수 있습니다. compare함수는 직접 구현해야 합니다.
sort(v.begin(), v.end(), compare);sort함수는 두가지 함수를 받아 비교 후, boolean을 통해 두 인자의 대소를 비교하여 정렬합니다.
DNA문제에서, 우리는 첫번째 인자가 제일 크도록, 두번째 인자는 사전순으로 제일 작은 수가 오도록 정렬하고 싶습니다.
sort함수가 요구하는 것 처럼, 우리가 원하는 정렬을 하도록 boolean을 반환하는 함수를 다음과 같이 작성해 봅시다.
설명이 있으니 일단 마음편히 보시면 될 것 같습니다!
bool compare(pair<int, char>& front, pair<int, char>& back)
{
int front_cnt = front.first;
char front_char = front.second;
int back_cnt = back.first;
char back_char = back.second;
if (front_cnt < back_cnt) return front_cnt > back_cnt;
else if (front_cnt == back_cnt) return front_char < back_char;
else return front_cnt > back_cnt;
}감이 살짝 오시나요? 한줄 한줄 무얼 의미하는지 살펴볼게요!
//함수의 선언부
bool compare(pair<int, char>& front, pair<int, char>& back)boolean 타입을 반환하는 compare 함수입니다. 이 함수는 내부적으로 pair을 받아 front, back에 저장하여 대소를 비교하여 결과를 반환합니다.
Q1. 엥?? pair가 왜 갑자기 나오나요??
A: 아까 위에서 이 문제를 정의할 때 v는 pair<int, char>의 짝꿍을 가지는 벡터였습니다. 이 함수에서 두개의 v의 pair를 비교하고 대소를 반환하기 위해 위같은 인자를 받도록 합니다.
int front_cnt = front.first;
char front_char = front.second;
int back_cnt = back.first;
char back_char = back.second;앞 뒤 pair를 비교하기 위해선, 각각을 변수로 나누어 비교해야겠죠! 위에서 나눴던 인자를 다시 나누어줍시다.
if (front_cnt < back_cnt) return front_cnt > back_cnt;
else if (front_cnt == back_cnt) return front_char < back_char;
else return front_cnt > back_cnt;제일 중요한 부분입니다.
우리는 first가 제일 크게, first가 서로 같다면, second가 제일 작은 정렬을 수행하고 싶습니다.
따라서 위의 return을 반환하면 내맘대로 정렬이 완료됩니다.
내맘대로 정렬을 이용한 정답은 다음과 같습니다.
#include <iostream>
#include <algorithm>
#include <vector>
#include <string>
using namespace std;
bool compare(pair<int, char>& front, pair<int, char>& back)
{
int front_cnt = front.first;
char front_char = front.second;
int back_cnt = back.first;
char back_char = back.second;
if (front_cnt < back_cnt) return front_cnt > back_cnt;
else if (front_cnt == back_cnt) return front_char < back_char;
else return front_cnt > back_cnt;
}
int main()
{
int n, m, shortest_cnt=0;
int hamming_field[1001] = { 0, };
string str[1001], shortest_dna;
cin >> n >> m;
for (int i = 0; i < n; i++) cin >> str[i];
for (int i = 0; i < m; i++)
{
vector<pair<int, char> > v;
int a_cnt = 0, c_cnt = 0, g_cnt = 0, t_cnt = 0;
for (int j = 0; j < n; j++)
{
if (str[j][i] == 'A') a_cnt++;
if (str[j][i] == 'C') c_cnt++;
if (str[j][i] == 'G') g_cnt++;
if (str[j][i] == 'T') t_cnt++;
}
v.push_back({ a_cnt, 'A' });
v.push_back({ c_cnt, 'C' });
v.push_back({ g_cnt, 'G' });
v.push_back({ t_cnt, 'T' });
sort(v.begin(), v.end(), compare);
shortest_cnt += n - v[0].first;
shortest_dna += v[0].second;
}
cout << shortest_dna << "\n" << shortest_cnt;
return 0;
}DIY compare함수 작성은 pair가 있는 정렬에서 유용하겠습니다.
이해가 되셨다면, 다음 문제도 풀어보세요!
Bonus - 14593번, 2017 아주대학교 프로그래밍 경시대회 (Large)
14593번: 2017 아주대학교 프로그래밍 경시대회 (Large)
아주대학교 프로그래밍 경시대회(Ajou Programming Contest, APC)는 2009년 제1회를 시작으로 2014년 제6회까지 개최된 아주대학교 학생들을 위한 프로그래밍 경시대회이다. 2017년, 다른 학교에서 활발히
www.acmicpc.net
세개의 정수가 순서대로 입력됩니다. 각각의 정수를 편의상 A, B, C라고 부르겠습니다.
여러 참가자중, A가 제일 큰 사람이 우승합니다.
A가 같은 경우, B가 더 작은 사람이 우승합니다.
A와 B가 모두 같은 경우, C가 더 작은 사람이 우승합니다.
흠.... 각각의 사람마다 많은 정보가 주어집니다. 그렇다면, 2개의 쌍을 가지는 벡터를 선언해 내맘대로 정렬을 해볼까요?
typedef pair<int, int> score_pare;
vector<pair <score_pare, score_pare> > v;
pair<int, int>는 항상 쓰기도 손목아프고, 보기도 좋지 않으니, score pare로 바꾸어 쓰겠습니다.
v는 다음과 같은 정보를 저장할 예정입니다.
V [pair(A, B), pair(C, 참가자 번호)]
여기서 질문입니다. V안에는 두개의 pair가 pair 자체로 묶여 저장되어 있습니다.
그렇다면, V.first.first는 뭘까~~~~~요??
바로바로, A입니다!!!!!
pair로 pair를 묶었기 때문에, V.first는 pair(A, B)이고, 여기서 또 V.first.first를 해주면, A가 선택된 것입니다.
꿈속의 꿈속을 탐험하는 인셉션처럼, 우리가 선언한 벡터는 Pair 속에 Pair를 선언한 것이죠.
그렇다면, 문제가 요구하는 것에 따라 내맘대로 정렬을 수행하기 위해 compare함수를 작성해 보겠습니다!
#include <iostream>
#include <algorithm>
#include <vector>
using namespace std;
typedef pair<int, int> score_pare;
vector<pair <score_pare, score_pare> > v;
bool compare(pair<score_pare, score_pare> &front, pair<score_pare, score_pare> &back)
{
int front_s = front.first.first;
int front_c = front.first.second;
int front_l = front.second.first;
int back_s = back.first.first;
int back_c = back.first.second;
int back_l = back.second.first;
if (front_s == back_s)
{
if (front_c == back_c) return front_l < back_l;
return front_c < back_c;
}
return front_s > back_s;
}pair속에 pair가 있는 인자를 각각 front와 back으로 받고, 각각을 변수로 나누어 비교하는 것을 보실 수 있습니다.
V.second.second는 [참가자의 번호]를 나타내고 있으므로 비교하지 않습니다. 정렬이 완료되면, 맨 앞 원소의 참가자 번호를 출력할거니까요!
정답코드는 다음과 같습니다.
#include <iostream>
#include <algorithm>
#include <vector>
using namespace std;
typedef pair<int, int> score_pare;
vector<pair <score_pare, score_pare> > v;
bool compare(pair<score_pare, score_pare> &front, pair<score_pare, score_pare> &back)
{
int front_s = front.first.first;
int front_c = front.first.second;
int front_l = front.second.first;
int back_s = back.first.first;
int back_c = back.first.second;
int back_l = back.second.first;
if (front_s == back_s)
{
if (front_c == back_c) return front_l < back_l;
return front_c < back_c;
}
return front_s > back_s;
}
int main()
{
int n;
int s, c, l;
cin >> n;
for (int i = 1; i <= n; i++)
{
cin >> s >> c >> l;
v.push_back({ {s,c},{l,i} });
}
sort(v.begin(), v.end(), compare);
cout<<v[0].second.second;
return 0;
}'알고리즘' 카테고리의 다른 글
| [BOJ] 14606번. 피자 (0) | 2021.01.22 |
|---|---|
| [BOJ] 1010번. 다리 놓기 (0) | 2021.01.21 |
| 실전 속성! C++ 이것만 알면 된다 (+ 간단 단축키 모음) (0) | 2021.01.18 |
| [BOJ] 1149번.RGB거리 (0) | 2021.01.10 |
| [BOJ] 15649번. N과 M(1) (0) | 2021.01.10 |