
나는 왜 여자 친구가 없을까?
3자가 본다면 바로 의심해볼 만할 구석이 있겠지만, 정작 자신은 받아들이기 힘든 이유가 있습니다.
제가 생각하는 연인이 있을 확률은 다음과 같습니다.
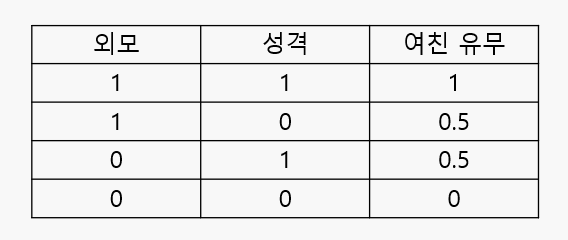
제가 생각하는 외모가 1인 사람은 원빈입니다.
머신러닝을 통해 제 얼굴을 원빈과 고릴라와 비교하여 보겠습니다.
이 과정에서 Siamese Network를 통한 얼굴인식, One_shot Learning에 대해서도 알아볼 수 있을 것입니다.
[One Shot Learning]
소규모의 데이터 혹은 한번 본 물체를 많은 데이터와 비교하고 분류할 때 사용하는 방법입니다.
기존의 딥러닝 방식은 Convolution network가 충분히 학습할 수 있도록 많은 양의 데이터를 요구합니다. 하지만 얼굴 인식에서는 많은 데이터 확보가 어렵습니다. 또한 많은 데이터를 학습하더라도, 같은 얼굴이 여러 상황(빛의 양, 얼굴 각도, 다른 배경 등)에 놓일 수 있으므로 기존 방식으로는 분류가 어렵습니다.
그래서 등장한 것이 One shot Learning입니다. 혹은 Few shot Learning으로도 불리는데요, 이 아이디어는 기존 알고 있는 학습 데이터와 새롭게 주어진 이미지의 거리를 판단하여 불일치도를 기준으로 판단합니다. 데이터 셋을 기반으로 한 분류가 아닌 불일치도를 기준으로 판단하기 때문에 데이터가 많이 필요하지 않고, 여러 상황에 놓인 같은 클래스를 분류해낼 수 있습니다. 사진으로 간단하게 살펴볼까요?

One-shot learning에 대해 알아보았습니다. 적은 데이터를 이용하여 유사도를 측정할 수 있다! 는 것이 골자인 것 같은데, 제일 중요한 이미지간의 거리를 구하는 법은 아직 설명하지 않았어요. 이 부분에 대해서는 바로 Siamese Network를 함께 보시면서 알아보겠습니다.
[Siamese Network]
읽을때는 샴 네트워크라고 발음합니다. 어떤 사람에 대해서 학습하고, 새로운 이미지에 대해서 같은 CNN의 잣대로 동일 인물인지 평가합니다. 기본적인 샴 네트워크 구조를 우선 사진으로 보겠습니다.

CNN에 대해서는 이미 잘 알고 있다고 가정하겠습니다. 입력된 이미지가 CNN을 통과해 벡터로 펼쳐진 후 비교되는 모습을 보실 수 있습니다. 삼중 비교는 잠시 뒤에 살펴보겠습니다.
샴 네트워크에서, 모든 이미지는 미리 학습된 CNN네트워크를 공유합니다. 이 CNN네트워크는 가중치와 파라미터가 모두 같은 상태입니다. 생각해보면 당연합니다. 새로 입력된 이미지가 데이터상의 이미지와 같은 사람인지 확인하려면, 같은 잣대로 판단해야 하겠죠.
예를 들어, 당신이 헬스장의 회원으로 등록되어있다고 하겠습니다. 이 헬스장의 회원증에는 당신의 ID와 사진이 등록되어있습니다. 헬스장에 입장하기 위해선 입구에서 ID를 입력하고 얼굴 인식을 해야합니다.
헬스장에 입장하기 위해 ID를 입력하는 순간, 얼굴 인식기에는 미리 학습해놓은 당신의 CNN을 불러올 것입니다. 당신의 얼굴을 스캔한 이 기기는 스캔한 이미지와 원본 얼굴의 거리를 측정하여 당신을 입장시킬지 말지 결정할 것입니다.
당연히 고릴라는 출입이 되지 않습니다.
이러한 과정이 원활하게 수행되기 위해서 미리 라벨링을 해줍니다.
당신과 같은 사람(Positive)인 경우 : 1
당신과 다른 사람(Negative)인 경우 : 0
이제 어떤 식으로 이미지에 거리를 측정하는지 알아보겠습니다.
[삼중항 손실(Triplet Loss Integration)]
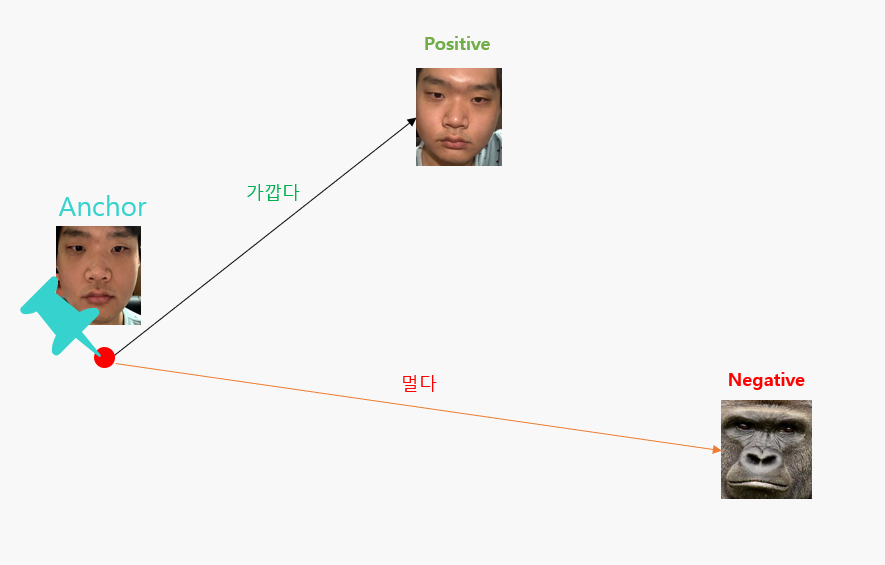
삼중항 손실은 앵커(Anchor, 기준점), 긍정 이미지(Positive), 부정 이미지(Negative)로 이루어져있습니다.
앵커 이미지는 새로 들어오는 이미지를 의미합니다. 긍정이미지는 앵커와 같은 인물을 의미하고, 부정이미지는 앵커와 다른 인물을 의미합니다. 학습을 통해 앵커와 긍정 이미지간의 거리는 가깝고 부정 이미지간의 거리는 멀도록 조정합니다.
아까 CNN의 마지막 단계에서 학습된 피처맵을 벡터로 쭉~ 피는 모습을 볼 수 있었습니다. 이미지간의 거리는 다음과 같은 식으로 계산할 수 있겠습니다.

우선 벡터의 길이만큼 다음의 정보들을 더하며 거리를 계산합니다.
F(x^a)는 앵커 이미지를 의미합니다.
F(x^p)는 앵커와 같은 사람, 그러니까 긍정 이미지를 의미하고, F(x^n)은 앵커와 다른 사람인 부정 이미지를 의미합니다.
알파는 마진을 의미합니다. 얼마간의 마진을 두어 학습이 잘되도록 조정합니다.
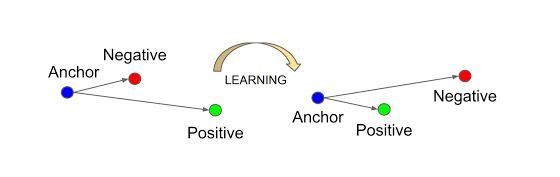
이미지간 거리 구하는 방법이 생각보다 간단하네요! 위 식이 등장한 배경도 그리 어렵지 않습니다. 다음 사진과 함께 보겠습니다.

우리는 원래 앵커와 긍정이미지간의 거리가 앵커와 부정 이미지간의 거리보다 가깝기를 원했습니다. 부등호의 방향을 보면 무엇을 의도했는지 알 수 있죠! 아까 이미지는 이 식의 우항을 좌변으로 넘긴 것에 지나지 않습니다.
샴 네트워크의 기본 개념이었습니다. 생각보다 간단한 이야기죠?? 그럼 다음 장에서 실제 구현 코드를 같이 보고 샴 네트워크의 구성 방법을 살펴보겠습니다.
'머신러닝' 카테고리의 다른 글
| [Pytorch] Siamese network를 이용하여 나의 외모를 점검해보자_2탄 (1) | 2021.02.27 |
|---|---|
| [Pytorch] 데이터를 뻥튀기하자! Data Augmentation (8) | 2021.02.13 |
| [입문] Pytorch 와 Linear Regression (0) | 2021.01.15 |
나는 왜 여자 친구가 없을까?
3자가 본다면 바로 의심해볼 만할 구석이 있겠지만, 정작 자신은 받아들이기 힘든 이유가 있습니다.
제가 생각하는 연인이 있을 확률은 다음과 같습니다.
제가 생각하는 외모가 1인 사람은 원빈입니다.
머신러닝을 통해 제 얼굴을 원빈과 고릴라와 비교하여 보겠습니다.
이 과정에서 Siamese Network를 통한 얼굴인식, One_shot Learning에 대해서도 알아볼 수 있을 것입니다.
[One Shot Learning]
소규모의 데이터 혹은 한번 본 물체를 많은 데이터와 비교하고 분류할 때 사용하는 방법입니다.
기존의 딥러닝 방식은 Convolution network가 충분히 학습할 수 있도록 많은 양의 데이터를 요구합니다. 하지만 얼굴 인식에서는 많은 데이터 확보가 어렵습니다. 또한 많은 데이터를 학습하더라도, 같은 얼굴이 여러 상황(빛의 양, 얼굴 각도, 다른 배경 등)에 놓일 수 있으므로 기존 방식으로는 분류가 어렵습니다.
그래서 등장한 것이 One shot Learning입니다. 혹은 Few shot Learning으로도 불리는데요, 이 아이디어는 기존 알고 있는 학습 데이터와 새롭게 주어진 이미지의 거리를 판단하여 불일치도를 기준으로 판단합니다. 데이터 셋을 기반으로 한 분류가 아닌 불일치도를 기준으로 판단하기 때문에 데이터가 많이 필요하지 않고, 여러 상황에 놓인 같은 클래스를 분류해낼 수 있습니다. 사진으로 간단하게 살펴볼까요?
One-shot learning에 대해 알아보았습니다. 적은 데이터를 이용하여 유사도를 측정할 수 있다! 는 것이 골자인 것 같은데, 제일 중요한 이미지간의 거리를 구하는 법은 아직 설명하지 않았어요. 이 부분에 대해서는 바로 Siamese Network를 함께 보시면서 알아보겠습니다.
[Siamese Network]
읽을때는 샴 네트워크라고 발음합니다. 어떤 사람에 대해서 학습하고, 새로운 이미지에 대해서 같은 CNN의 잣대로 동일 인물인지 평가합니다. 기본적인 샴 네트워크 구조를 우선 사진으로 보겠습니다.
CNN에 대해서는 이미 잘 알고 있다고 가정하겠습니다. 입력된 이미지가 CNN을 통과해 벡터로 펼쳐진 후 비교되는 모습을 보실 수 있습니다. 삼중 비교는 잠시 뒤에 살펴보겠습니다.
샴 네트워크에서, 모든 이미지는 미리 학습된 CNN네트워크를 공유합니다. 이 CNN네트워크는 가중치와 파라미터가 모두 같은 상태입니다. 생각해보면 당연합니다. 새로 입력된 이미지가 데이터상의 이미지와 같은 사람인지 확인하려면, 같은 잣대로 판단해야 하겠죠.
예를 들어, 당신이 헬스장의 회원으로 등록되어있다고 하겠습니다. 이 헬스장의 회원증에는 당신의 ID와 사진이 등록되어있습니다. 헬스장에 입장하기 위해선 입구에서 ID를 입력하고 얼굴 인식을 해야합니다.
헬스장에 입장하기 위해 ID를 입력하는 순간, 얼굴 인식기에는 미리 학습해놓은 당신의 CNN을 불러올 것입니다. 당신의 얼굴을 스캔한 이 기기는 스캔한 이미지와 원본 얼굴의 거리를 측정하여 당신을 입장시킬지 말지 결정할 것입니다.
당연히 고릴라는 출입이 되지 않습니다.
이러한 과정이 원활하게 수행되기 위해서 미리 라벨링을 해줍니다.
당신과 같은 사람(Positive)인 경우 : 1
당신과 다른 사람(Negative)인 경우 : 0
이제 어떤 식으로 이미지에 거리를 측정하는지 알아보겠습니다.
[삼중항 손실(Triplet Loss Integration)]
삼중항 손실은 앵커(Anchor, 기준점), 긍정 이미지(Positive), 부정 이미지(Negative)로 이루어져있습니다.
앵커 이미지는 새로 들어오는 이미지를 의미합니다. 긍정이미지는 앵커와 같은 인물을 의미하고, 부정이미지는 앵커와 다른 인물을 의미합니다. 학습을 통해 앵커와 긍정 이미지간의 거리는 가깝고 부정 이미지간의 거리는 멀도록 조정합니다.
아까 CNN의 마지막 단계에서 학습된 피처맵을 벡터로 쭉~ 피는 모습을 볼 수 있었습니다. 이미지간의 거리는 다음과 같은 식으로 계산할 수 있겠습니다.
우선 벡터의 길이만큼 다음의 정보들을 더하며 거리를 계산합니다.
F(x^a)는 앵커 이미지를 의미합니다.
F(x^p)는 앵커와 같은 사람, 그러니까 긍정 이미지를 의미하고, F(x^n)은 앵커와 다른 사람인 부정 이미지를 의미합니다.
알파는 마진을 의미합니다. 얼마간의 마진을 두어 학습이 잘되도록 조정합니다.
이미지간 거리 구하는 방법이 생각보다 간단하네요! 위 식이 등장한 배경도 그리 어렵지 않습니다. 다음 사진과 함께 보겠습니다.
우리는 원래 앵커와 긍정이미지간의 거리가 앵커와 부정 이미지간의 거리보다 가깝기를 원했습니다. 부등호의 방향을 보면 무엇을 의도했는지 알 수 있죠! 아까 이미지는 이 식의 우항을 좌변으로 넘긴 것에 지나지 않습니다.
샴 네트워크의 기본 개념이었습니다. 생각보다 간단한 이야기죠?? 그럼 다음 장에서 실제 구현 코드를 같이 보고 샴 네트워크의 구성 방법을 살펴보겠습니다.
'머신러닝' 카테고리의 다른 글
| [Pytorch] Siamese network를 이용하여 나의 외모를 점검해보자_2탄 (1) | 2021.02.27 |
|---|---|
| [Pytorch] 데이터를 뻥튀기하자! Data Augmentation (8) | 2021.02.13 |
| [입문] Pytorch 와 Linear Regression (0) | 2021.01.15 |